
We introduce FLAG-4D, a novel framework for generating novel views of dynamic scenes by reconstructing how 3D Gaussian primitives evolve through space and time. Existing methods typically rely on a single Multilayer Perceptron(MLP) to model temporal deformations, and they often struggle to capture complex point motions and fine-grained dynamic details consistently over time, especially from sparse input views.
Our approach, FLAG-4D overcomes this by employing a dual-deformation network that dynamically warps a canonical set of 3D Gaussians over time into new positions and anisotropic shapes. This dual-deformation network consists of an Instantaneous Deformation Network (IDN) for modeling fine-grained, local deformations, and Global Motion Network (GMN) for capturing long-range dynamics, refined via mutual learning.
To ensure these deformations are both accurate and temporally smooth, FLAG-4D incorporates dense motion features from a pretrained optical flow backbone. We fuse these motion cues from adjacent timeframes and use a deformation-guided attention mechanism to align this flow information with the current state of each evolving 3D Gaussian. Extensive experiments demonstrate that FLAG-4D achieves higher-fidelity and more temporally coherent reconstructions with finer detail preservation than state-of-the-art methods.
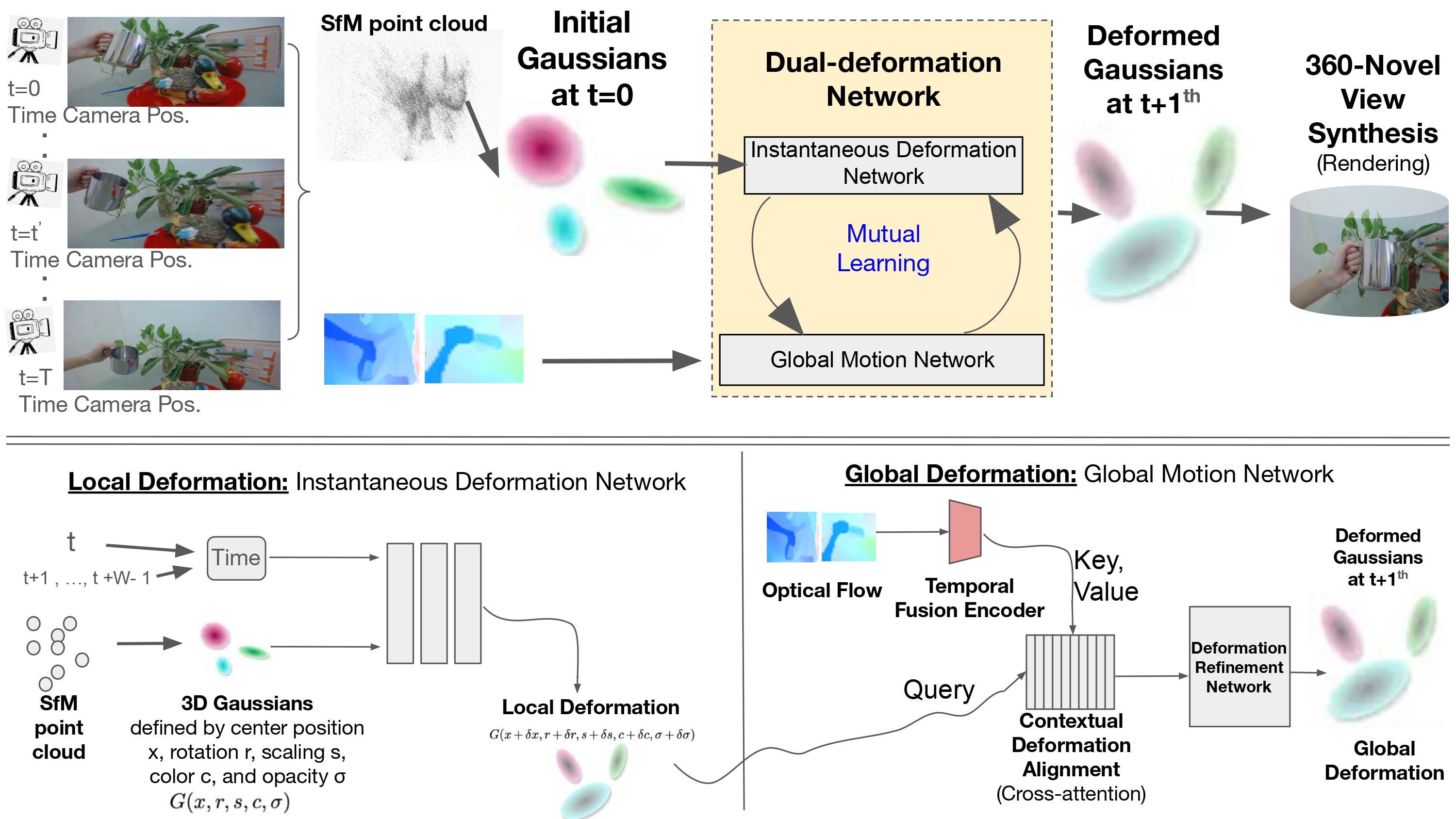
Figure 2: FLAG-4D Methodology: Our dual-deformation framework for 4D reconstruction. Top: The overall pipeline: A monocular video sequence is used to generate an initial SfM point cloud, from which a canonical set of 3D Gaussians at t=0 is derived. The Dual-Deformation Network consists of an Instantaneous Deformation Network (IDN) and a Global Motion Network (GMN), which are trained synergistically via Mutual Learning. Bottom Left: The IDN processes the canonical Gaussians and a window of future-oriented time embeddings to produce a hypothesized local deformation. Bottom Right: The GMN integrates this local deformation hypothesis (as Query) with fused optical flow embeddings (as Key/Value) via a cross-attention mechanism, producing the final globally consistent deformation.

Figure 4: Qualitative comparisons on NeRF-DS dataset. Our method captures finer details and preserves complex structures better than baselines like SC-GS, D-MiSo, and 4DGS.
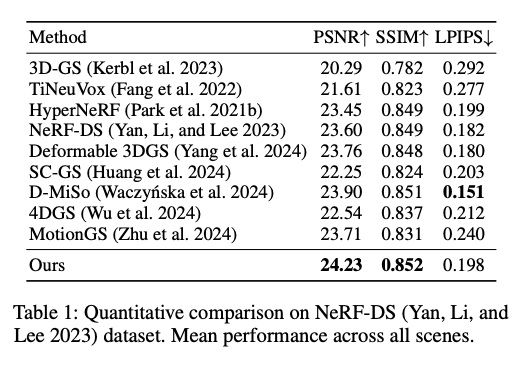
Table 1: Quantitative comparison on NeRF-DS (Yan, Li, and Lee 2023) dataset. Mean performance across all scenes.

Detailed ablation studies demonstrating the effectiveness of our dual-deformation network and flow-guided attention mechanism.
@article{tan2026flag4d,
author = {Tan, Guan Yuan and Vu, Ngoc Tuan and Pal, Arghya and Rajanala, Sailaja and Phan, Raphael CW and Srinivas, Mettu and Ting, Chee-Ming},
title = {FLAG-4D: Flow Guided Local-global Dual-deformation Model for 4D Reconstruction},
journal = {AAAI},
year = {2026},
}