Methodology
Herald operates by orchestrating a coalition of open-source LLMs. It decomposes complex visual tasks into executable Python programs, leveraging the collective intelligence of smaller, freely available models to rival proprietary giants.

Premium large language models (LLMs) such as GPT-4 offer impressive multimodal performance, yet their paywall limits both accessibility and reproducibility. We ask whether a coalition of freely-accessible LLMs—each individually noisy and uncertain—can collectively rival or surpass their premium counterparts when treated as collaborative, on-the-fly programmers.
We present Herald, a framework that (i) primes a diverse pool of zero-cost API LLMs with chain-of-thought cues, (ii) harvests their responses as human-readable Python fragments, control-flow branches, and live API calls, and (iii) employs a rank-and-fuse module to assemble the best fragments into a single executable script. The resulting program is executed by an Executor that produces the task output and a fully inspectable reasoning trace.
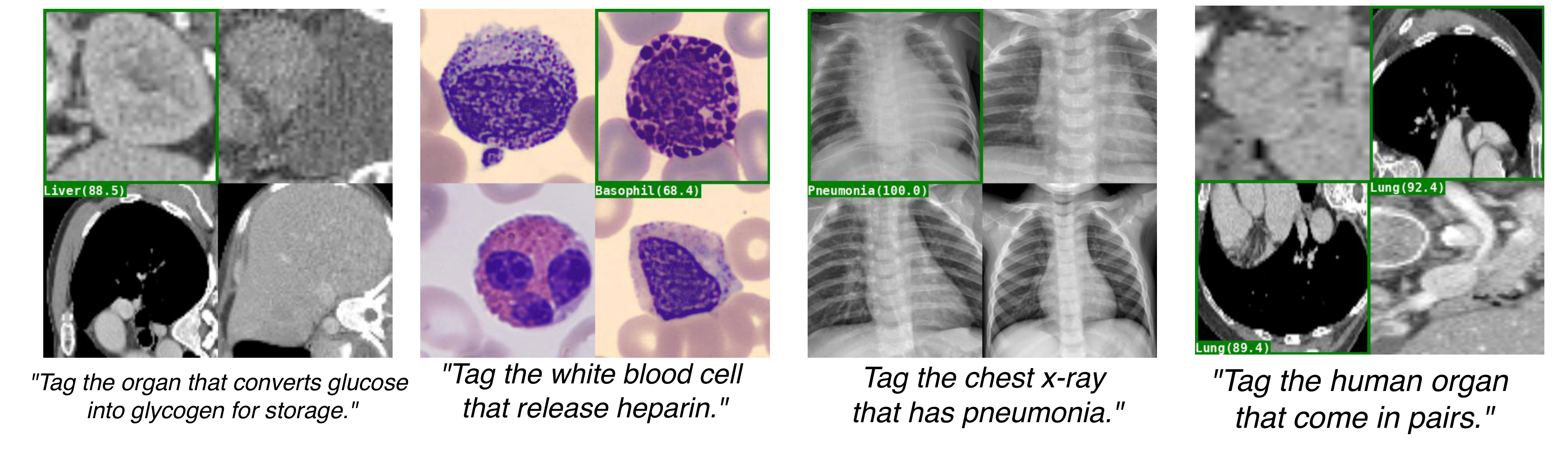
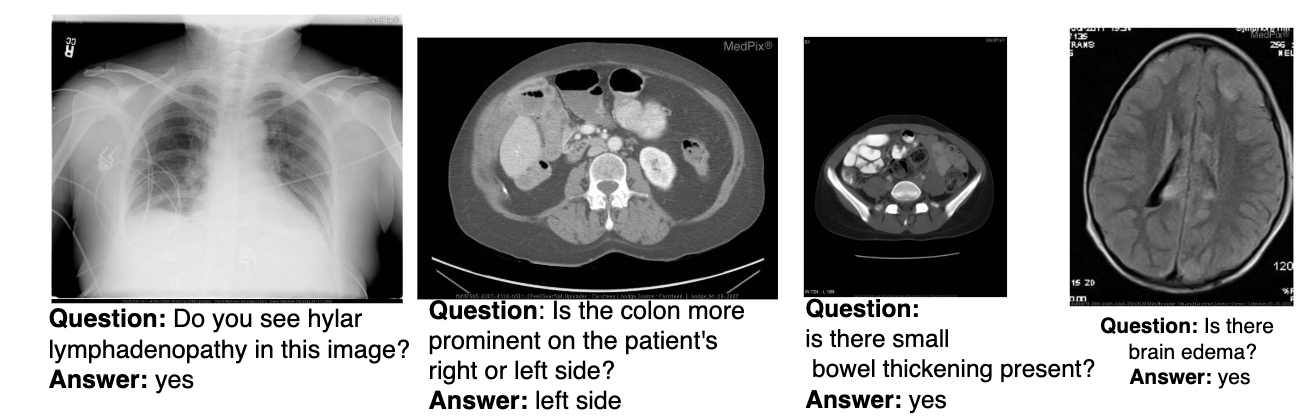
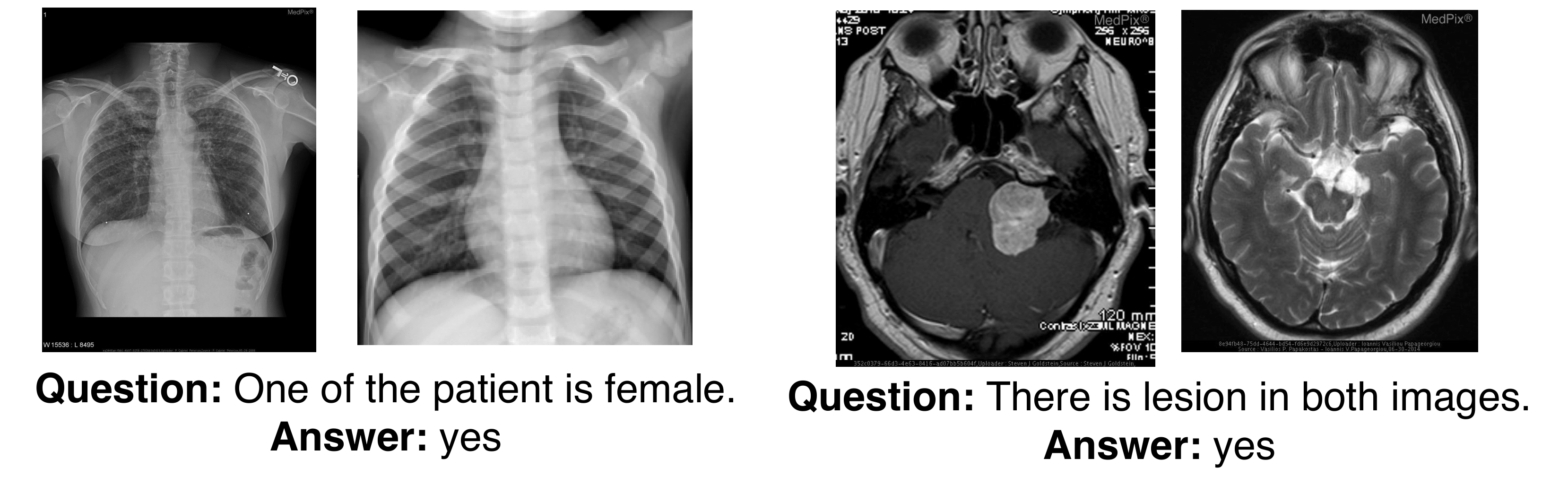
Without any additional training, Herald tackles heterogeneous vision workloads—image editing, semantic tagging, and medical triage—and achieves state-of-the-art or better accuracy on both medical and non-medical benchmarks. By transforming latent model competence into legible artefacts, Herald enables a transparent interaction style that invites user scrutiny, iterative refinement, and accountable auditing.
Herald operates by orchestrating a coalition of open-source LLMs. It decomposes complex visual tasks into executable Python programs, leveraging the collective intelligence of smaller, freely available models to rival proprietary giants.
We demonstrate Herald's capabilities across various domains including image editing, semantic tagging, and medical triage.



@article{tan2025herald,
author = {Tan, Guan-Yuan and Pal, Arghya and Rajanala, Sailaja and Phan, Raphaël C.-W. and Ting, Chee-Ming},
title = {Herald: Democratizing Compositional Reasoning for Visual Tasks without Any Training},
conference = {APSIPA ASC},
year = {2025},
}